UMA和NUMA之间的区别

内容

多处理器可以分为三个共享内存模型类别-UMA(统一内存访问),NUMA(非统一内存访问)和COMA(仅缓存内存访问)。根据内存和硬件资源的分配方式来区分模型。在UMA模型中,物理内存在处理器之间平均共享,每个内存字的等待时间也相等,而NUMA为处理器访问内存提供了可变的访问时间。
UMA中使用的内存带宽被限制,因为它使用单个内存控制器。 NUMA机器问世的主要目的是通过使用多个内存控制器来增加内存的可用带宽。
-
- 比较表
- 定义
- 关键差异
- 结论
比较表
| 比较依据 | UMA | NUMA |
|---|---|---|
| 基本的 | 使用单个内存控制器 | 多存储控制器 |
| 使用的巴士类型 | 单,多和交叉开关。 | 树和层次 |
| 内存访问时间 | 等于 | 根据微处理器的距离而变化。 |
| 适用于 | 通用和分时应用 | 实时和时间关键型应用 |
| 速度 | 慢点 | 快点 |
| 带宽 | 有限 | 不仅仅是UMA。 |
UMA的定义
UMA(统一内存访问) 系统是多处理器的共享内存体系结构。在此模型中,借助于互连网络,由多处理器系统中的所有处理器使用并访问单个存储器。每个处理器具有相等的内存访问时间(延迟)和访问速度。它可以采用单总线,多总线或纵横开关。由于它提供平衡的共享内存访问,因此也称为 SMP(对称多处理器) 系统。
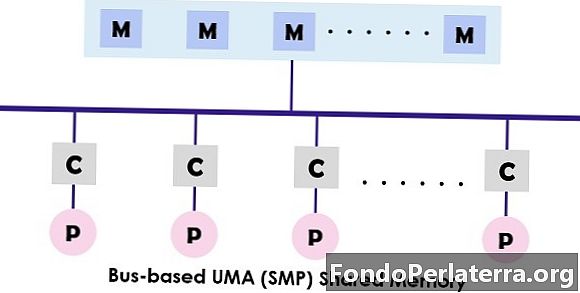
上面显示了SMP的典型设计,其中每个处理器首先连接到高速缓存,然后将高速缓存链接到总线。最后,总线连接到存储器。这种UMA体系结构通过直接从各个隔离的高速缓存中获取指令来减少总线争用。它还为读取和写入每个处理器提供了相等的概率。 UMA模型的典型示例是Sun Starfire服务器,Compaq alpha服务器和HP v系列。
NUMA的定义
NUMA(非统一内存访问) 也是多处理器模型,其中每个处理器都与专用内存连接。但是,存储器的这些小部分合并在一起构成一个地址空间。这里要考虑的主要问题是,与UMA不同,内存的访问时间取决于处理器放置的距离,这意味着内存访问时间会有所不同。它允许使用物理地址访问任何内存位置。
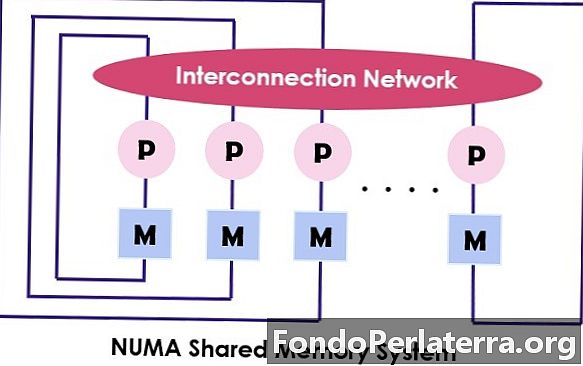
如上所述,NUMA体系结构旨在增加内存的可用带宽,并为此使用多个内存控制器。它将众多机器核心整合为“节点每个内核都有一个内存控制器。要访问NUMA计算机中的本地内存,核心将通过其节点检索由内存控制器管理的内存。在访问由另一个内存控制器处理的远程内存时,核心通过互连链接发出内存请求。
NUMA体系结构使用树和分层总线网络将内存块和处理器互连。 BBN,TC-2000,SGI Origin 3000,Cray是NUMA体系结构的一些示例。
- UMA(共享内存)模型使用一个或两个内存控制器。与之相反,NUMA可以具有多个内存控制器来访问内存。
- UMA体系结构中使用了单,多和交叉开关总线。相反,NUMA使用分层的树型总线和网络连接。
- 在UMA中,每个处理器的内存访问时间相同,而在NUMA中,内存访问时间随着内存与处理器之间的距离的变化而变化。
- 通用和分时应用适用于UMA机器。相反,适用于NUMA的应用程序是实时且以时间为中心的。
- 基于UMA的并行系统的运行速度比NUMA系统慢。
- 当涉及到带宽UMA时,请限制带宽。相反,NUMA具有比UMA更多的带宽。
结论
UMA体系结构为访问内存的处理器提供了相同的总体延迟。当访问本地内存时,这不是很有用,因为等待时间是统一的。另一方面,在NUMA中,每个处理器都有其专用内存,从而消除了访问本地内存时的延迟。延迟随着处理器和存储器之间的距离的改变而改变(即,不均匀)。但是,与UMA架构相比,NUMA改善了性能。





