快速排序和合并排序之间的区别
作者:
Laura McKinney
创建日期:
1 四月 2021
更新日期:
13 可能 2024

内容

快速排序和合并排序算法基于分而治之的算法,其工作原理非常相似。快速排序和合并排序之间的先有区别是,在快速排序中,枢轴元素用于排序。另一方面,合并排序不使用数据透视元素来执行排序。
快速排序和合并排序这两种排序技术都建立在分而治之的方法上,在该方法中,元素集被分割,然后在重新排列后合并。快速排序通常比合并排序需要更多的比较,以对大量元素进行排序。
-
- 比较表
- 定义
- 关键差异
- 结论
比较表
| 比较依据 | 快速分类 | 合并排序 |
|---|---|---|
| 数组中元素的分区 | 元素列表的划分不一定要分为两半。 | 数组总是分为一半(n / 2)。 |
| 最坏情况下的复杂性 | 上2) | O(n log n) |
| 运作良好 | 较小的阵列 | 在任何类型的数组中均可正常运行。 |
| 速度 | 对于小型数据集,比其他排序算法更快。 | 所有类型的数据集中的速度一致。 |
| 额外的存储空间要求 | 减 | 更多 |
| 效率 | 对于较大的阵列效率低下。 | 更高效。 |
| 排序方式 | 内部 | 外部 |
快速排序的定义
快速分类 被广泛使用的排序算法,因为它对短数组的速度很快。元素的集合被重复地划分为多个部分,直到不可能进一步划分为止。快速排序也称为 分区交换排序。它使用键元素(称为枢轴)对元素进行分区。一个分区包含的元素小于关键元素。另一个分区包含的元素大于关键元素。元素以递归方式排序。
假设A是必须排序的n个数组A,A,A,……..,A。快速排序算法包括以下步骤。
- 选择第一个元素或任何随机元素作为键,假定键= A(1)。
- “ low”指针位于数组的第二个元素,“ up”指针位于数组的最后一个元素,即low = 2和up = n;
- 始终将“低”指针增加一个位置,直到(A>键)。
- 不断地将“上”指针递减一个位置,直到(A <= key)。
- 如果向上大于向下,则将A与A互换。
- 重复步骤3,4和5,直到步骤5中的条件失败(即up <= low),然后将A与密钥互换。
- 如果键左边的元素小于键,而键右边的元素大于键,则将数组划分为两个子数组。
- 上面的过程将重复应用于子数组,直到整个数组被排序为止。

的优点和缺点
它具有良好的平均情况行为。快速排序的运行时间复杂度很好,因为它比气泡排序,插入排序和选择排序之类的算法要快。但是,它很复杂且非常递归,这就是它不适用于大型数组的原因。
合并排序的定义
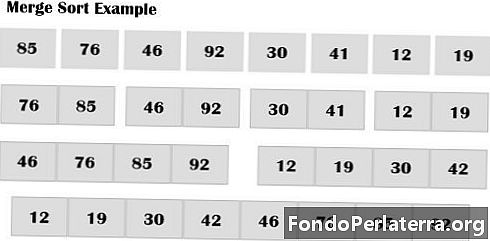
合并排序 是一种外部算法,它也是基于分而治之的策略。元素一次又一次地分成子数组(n / 2),直到只剩下一个元素为止,这大大减少了排序时间。它使用其他存储来存储辅助阵列。合并排序使用三个数组,其中两个用于存储每个一半,第三个用于存储最终的排序列表。然后将每个数组递归排序。最后,将子数组合并以使其成为数组的n个元素大小。与快速排序不同,该列表总是分为一半(n / 2)。
令A为要排序的n个元素的数组A,A,………,A。合并排序遵循给定的步骤。
- 将数组A分成2个约n / 2个排序的子数组,这意味着(A,A),(A,A),(A,A),(A,A)子数组中的元素必须排序。
- 组合每对对以获得大小为4的已排序子数组的列表;子数组中的元素也按排序顺序((A,A,A,A),……,(A,A,A,A),……。,(A,A,A,A)。
- 重复执行步骤2,直到只有一个大小为n的排序数组为止。
的优点和缺点
合并排序算法以完全相同和精确的方式执行,而不管排序中涉及的元素数量如何。即使使用大数据集,它也可以正常工作。但是,它占用了很大一部分内存。
- 在合并排序中,必须将数组分成两半(即n / 2)。相反,在快速排序中,没有强迫将列表分为相等的元素。
- 快速排序的最坏情况复杂度是O(n2),因为在最坏的情况下需要进行更多的比较。相反,合并排序具有最差情况和平均情况相同的复杂度,即O(n log n)。
- 合并排序可以在任何类型的数据集上(无论大小)都可以很好地运行。相反,快速排序不适用于大型数据集。
- 在某些情况下(例如对于小型数据集),快速排序比合并排序快。
- 合并排序需要额外的内存空间来存储辅助阵列。另一方面,快速排序不需要太多空间来额外存储。
- 合并排序比快速排序更有效。
- 快速排序是一种内部排序方法,可以在主内存中一次调整要排序的数据。相反,合并排序是一种外部排序方法,其中要排序的数据无法同时容纳在存储器中,而某些数据必须保留在辅助存储器中。
结论
快速排序是较快的情况,但在某些情况下效率不高,并且与合并排序相比,还执行很多比较。尽管合并排序所需的比较少,但它需要0(n)的额外存储空间来存储额外的数组,而快速排序则需要O(log n)的空间。





